In de wereld van gegevensverwerking en -opslag, is het Data Lake (in het Nederlands ook wel 'datameer' genoemd) een nieuwe vorm van (big) dataopslag. Maar wat is het verschil tussen deze meren en de huidige data warehouses? En wat is het nut? In dit blog varen we een stukje mee op het Data Lake.
Gestructureerde versus ruwe data
De term data lake werd in 2010 voor het eerst in een blog van de CTO van Business Intelligence specialist Pentaho, James Dixon genoemd. Hij omschreef het alsvolgt: “Een datamart/warehouse kan je vergelijken met een winkel voor flesjes bronwater. Het water is gezuiverd, gestructureerd verpakt en op deze manier geschikt voor eenvoudige consumptie. Een data lake is dan de waterbron in haar natuurlijke staat. De inhoud van de bron is ook water, maar ongezuiverd en nog niet verpakt. De waterbron kan bovendien ook voor andere doeleinden gebruikt worden.”
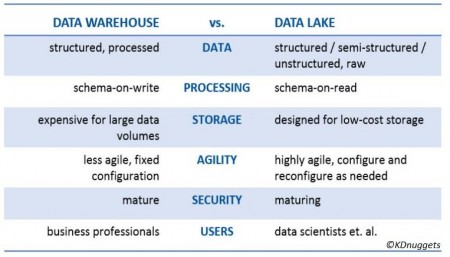
Verschil tussen het 'traditionele' data warehouse en een data lake. Bron: KDnuggets
Een van de grootste verschillen tussen data warehouses en data lakes, is dat data warehouses bestaan uit vooraf gestructureerde data. Dit heeft als voordeel dat je eenvoudiger antwoorden krijgt op vragen zoals bijvoorbeeld prijsontwikkelingen en de hoeveelheid verkochte producten. Data lakes daarentegen worden gebruikt om de veel grotere hoeveelheden aan ruwe (ongestructureerde) data te verzamelen. Deze data wordt opgeslagen en kan daarna voor verschillende doeleinden worden geanalyseerd. TechTarget legt het al volgt uit:
“While a hierarchical data warehouse stores data in files or folders, a data lake uses a flat architecture to store data. Each data element in a lake is assigned a unique identifier and tagged with a set of extended metadata tags. When a business question arises, the data lake can be queried for relevant data, and that smaller set of data can then be analyzed to help answer the question.”

Data lakes worden gebruikt om grote hoeveelheden aan
ruwe (ongestructureerde) data te verzamelen.
Vraag naar ongestructureerde data stijgt
Mede door de komst van sociale media, bleek al dat het voor data warehouses lastig was om met ongestructureerde data te werken. En omdat organisaties tegenwoordig een grotere diversiteit (en hoeveelheid) aan ongestructureerde data willen analyseren, gebruiken en managen, is het noodzakelijk dat ook de ‘traditionele’ datamagazijnen zich verder ontwikkelen. Oracle zette de 10 grootste voorspellingen voor big data ontwikkelingen voor grote en kleine organisaties op een rijtje.
Bekijk hieronder ook de uitleg over data lakes door data-opslagbedrijf en software ontwikkelaar Oracle:
Voordelen van een data lake
Door grote stukken ongestructureerde data tegen lage kosten op te vangen en verschillende soorten data op dezelfde plek op te slaan, onderscheidt een data lake zich in de volgende eigenschappen:
- Stelt analisten in staat om onderlinge relaties tussen nieuwe data te ontdekken. Het zuiveren van data kan worden uitgevoerd zodra daar behoefte aan is.
- Levert sneller resultaat dan de traditionele data aanpak. Een data lake zorgt voor een platform dat bergen data gebruiksklaar maakt voor business doeleinden, bijna real-time. Flexibel, efficiënt en snel. Een voorwaarde is echter wel dat er genoeg kennis moet zijn over het gebruik van big data.

De data-explosie en opkomst van nieuwe verwerkings-
en opslagmogelijkheden stelt hoge eisen aan de technische infrastructuren
Hoge eisen technische infrastructuur
De huidige data-explosie en opkomst van nieuwe verwerkings- en opslagmogelijkheden stelt uiteraard ook hoge eisen aan de technische infrastructuren van bedrijven, vooral aan die van data centers. Sterke concurrentie heeft ertoe geleid dat de kosten van bijvoorbeeld processor-, opslagcapaciteit sterk zijn gedaald. Ook ontwikkelingen zoals 'open architecture' en de onderlinge uitwisselbaarheid van onderdelen werken kostenreducerend.
Het onderhoud op de hardware vormt echter een grote uitzondering op de regel. Terwijl de hoeveelheid data alleen maar toeneemt en de hardware zelf een commodity is geworden, blijft het hardware-onderhoud een melkkoe voor de fabrikant, met name op het gebied van server, storage en netwerkensystemen. Ondanks het feit dat de budgetten onder druk staan, zijn niet alle organisaties ervan op de hoogte dat je voor dit type onderhoud niet per definitie afhankelijk bent van de fabrikant. Aangespoord door de huidige economische omstandigheden zijn er gespecialiseerde service providers die 'third party maintenance' aanbieden, waardoor men ook op het hardware-onderhoud een kostenbesparing realiseert.
Benieuwd naar de mogelijkheden? Vul dan ons contactformulier in.
Een email naar info.nl@econocom.com sturen is uiteraard ook mogelijk, wij zijn u graag van dienst!



